Quote:
Originally Posted by godleydemon
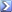
Interestingly enough, I've been using perchance for quite a while. I have a pretty extensive list of key words I normally use to get good generations. But with the current change, you have to be more descriptive. Which has posed it's own problems but opened interesting doors to generation.
This was my most recent attempts prompt
I think what's more unique about my approach is probably my Negatives.
As you can see, I have quite a few negatives but it produces some pretty good results. I included a few results I've gotten with this setup to create sudo AR. Let me make this clear, I do not believe this goes against any of our rules here. As the woman in question is still of age, but smaller, skinnier and petite at the end 
I'm unsure if indicating height, breast size, ect. will help much in generation if I'm being honest. The generator seems to like word descriptions like small, medium, large, extra large, huge, gigantic, humongous, gargantuan, ect. I also like using mature, curvy, petite, tiny and skinny. The generator just seems to understand this more instead of specific measurements. I've also found simply putting, "the middle image will always be the half way point between the left and right" seems to create pretty decent transitions without having to be specific. The generator just kind of figures it out. When I get off work tonight I'll play around with including some of OP's descriptions. For example, I get pretty interesting results when I include "It's a dramatic breathtaking best quality masterpiece with hyper-realistic anatomically correct proportions and intricate detail and composition by a top rated fetish artist on DeviantArt." that seems to up the quality of the generation. The last image in my attachments is with that sentence included. |
Your description of the middle image looks to get good consistency, in terms of being an interpolation of the right and left images. It strikes me that there should be some advantage in describing the left part of an image first, because the AI training data will be dominated by English, a language read left to right (including in art).
As far as specific terms versus more general ones, I think the key is to avoid terms without multiple meanings. For instance, I wanted a character with a "braided leather belt" recently, and it inevitably wanted to give her braided hair. It tends to grab the first definition or most common use of a word and try to depict that. So "Caucasian woman" will give you a light European skin tone and features, while "White woman" may just put something white somewhere in the scene.
The generic 'how to make a good image' terms are wild to me. You literally just tell it "it should look really good" and "don't make it look bad" and it yields better results. Just imagine if telling a human artist to "do better!" was all it took for improvement!

They're important, but at the same time it's something you get to a good place once, and then once you're getting good images in general you can focus on getting the subject and setting you want.